
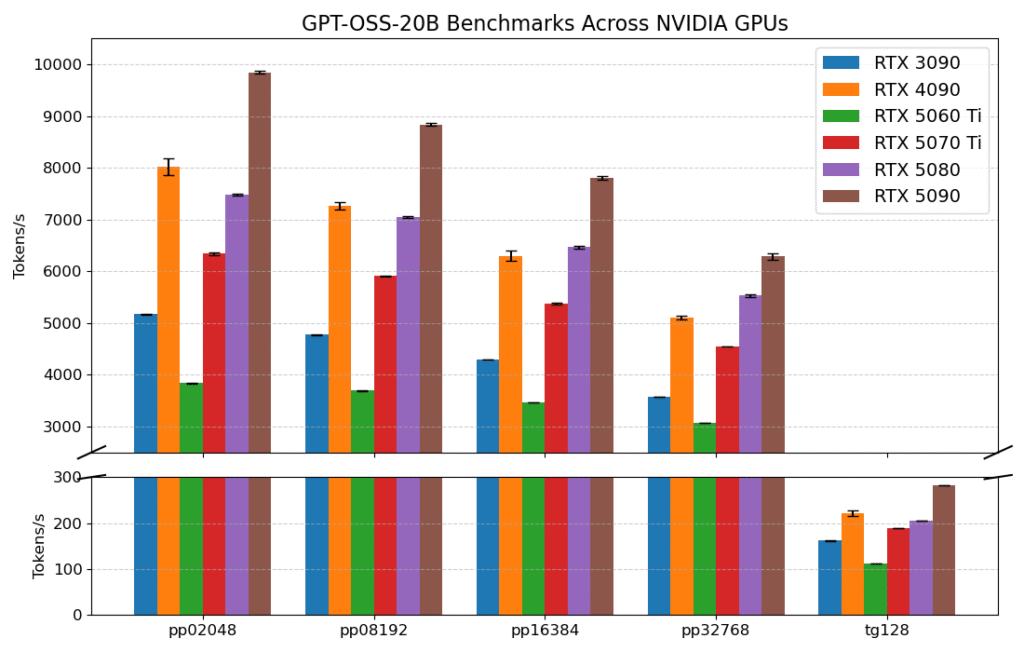
O Llama.cpp publicou seus próprios testes do gpt-oss-20b, mostrando que a GeForce RTX 5090 liderou com impressionantes 282 tok/s. Isso em comparação com o Mac M3 Ultra (116 tok/s) e o AMD 7900 XTX (102 tok/s).
Isso acontece porque a GeForce RTX 5090 inclui Tensor Cores integrados, projetados para acelerar tarefas de IA, maximizando o desempenho ao executar gpt-oss-20b localmente.
A medida “tok/s”, ou tokens por segundo, mede tokens, um pedaço de texto que o modelo lê ou gera em uma única etapa, e a rapidez com que eles podem ser processados.
O Llama.cpp é um framework de código aberto que permite executar LLMs (Large Language Models) com ótimo desempenho. E a execução é especialmente boa em GPUs RTX graças às otimizações feitas em colaboração com a NVIDIA.
Para entusiastas de IA que desejam apenas usar LLMs locais com essas otimizações da NVIDIA, pode-se considerar o uso do aplicativo LM Studio, desenvolvido sobre o Llama.cpp. O programa adiciona suporte para RAG (geração aumentada por recuperação) e foi projetado para facilitar a execução e a experimentação com LLMs.
A principal vantagem é que ele retira a necessidade de lidar com ferramentas de linha de comando ou configurações técnicas complexas.
Notícias Relacionadas:
- Microsoft planeja Windows guiado pelo Copilot e baseado em conversas
- Tá de wallhack na vida real: novo capacete EagleEye traz realidade mista com selo do criador do Oculus
- Investimentos em IA vão dificultar acesso de consumidores a hardwares, alerta ADATA
IAs Locais

Desenvolvedores e criadores que buscam maior controle e privacidade no uso de IA estão recorrendo a modelos executados localmente, como a nova família de modelos gpt-oss da OpenAI. Eles são leves e incrivelmente funcionais em hardware de usuário doméstico.
Isso significa que é possível executá-los em GPUs com apenas 16 GB de memória. Ou seja, é possível usar ampla gama de hardware, com as GPUs NVIDIA emergindo como a melhor maneira de executar esses tipos de modelos.

Enquanto países e empresas se apressam para desenvolver suas próprias soluções de IA sob medida para uma variedade de tarefas grandes e complexas, modelos de código aberto, como o novo gpt-oss-20b da OpenAI, estão encontrando muito mais adoção.
E este lançamento mais recente é praticamente comparável ao modelo GPT-4o mini.
O modelo também apresenta o raciocínio por cadeia de pensamento para analisar problemas profundamente, níveis de raciocínio ajustáveis para ajustar as capacidades de raciocínio em tempo real, comprimento de contexto expandido e ajustes de eficiência para ajudá-lo a rodar em hardware local.
Outras opções

Outro framework de código aberto popular para testes e experimentação de IA é o Ollama. Ele é ótimo para testar diferentes modelos de IA, incluindo os modelos OpenAI gpt-oss. E a NVIDIA trabalhou em estreita colaboração para otimizar o desempenho.
O Ollama gerencia downloads de modelos, configuração de ambiente e aceleração de GPU automaticamente. Ele também faz gerenciamento de modelos integrados para suportar múltiplos modelos simultaneamente, integrando-se facilmente com aplicativos e fluxos de trabalho locais.
De forma semelhante ao llama.cpp, outros aplicativos também utilizam o Ollama para executar LLMs. Um exemplo é o AnythingLLM, com sua interface local e direta, sendo excelente para quem está começando a fazer benchmarking de LLM.
Custo
Independentemente do aplicativo que usado para testar o gpt-oss-20b, as GPUs NVIDIA Blackwell mais recentes parecem oferecer o melhor desempenho. O problema principal é o custo, pois uma RTX 5090 sai por até R$ 26.773,51 na Kabum.
Modelos RTX 5080 também podem ser salgados, com a Gaming Trio OC da MSI saindo por R$ 24.499,00, mas havendo opções mais acessíveis como a ASUS ROG Astral por R$ 14.999,99.
Modelos da RTX 5070 saem pela metade desse valor, com a GAMING OC da Gigabyte saindo por R$ 7.099,99. Optando por um modelo RTX 5070 Ti, os preços são mais altos, chegando a R$ 10.101,66 (Solid OC da Zotac).
As coisas ficam mais acessíveis nos modelos RTX 5060 Ti, que sai por até R$ 3.499,99 (ASUS DUAL). No caso das RTX 5050, é possível adquirir pela metade desse valor, R$ 1.759,99 (Palit), mas o desempenho justifica um investimento maior.
Fonte: Github.

