
A NVIDIA divulgou recentemente as informações do GB300 Blackwell Ultra, seu mais recente e melhor chip de IA. Ele está em plena produção e já foi lançado para alguns dos clientes da empresa. Embora seja uma extensão da solução Blackwell, ele oferece uma atualização significativa em termos de desempenho e recursos.
A comparação mais simples é com as série Super de GPUs. Ou seja, a série Ultra é uma versão aprimorada dos chips de IA que foram lançados inicialmente.
A NVIDIA não tinha ofertas Ultra nas linhas anteriores, como Hopper e Volta, mas essas também tinham versões Ultra ou aprimoradas. Além disso, embora os chips Ultra sejam melhores em termos de hardware, atualizações e otimizações de software também oferecem ganhos substanciais em chips não Ultra ou não aprimorados.
Notícias Relacionadas:
- Driver GeForce 581.08 traz novas funcionalidades ao NVIDIA App
- NVIDIA adiciona 13 jogos ao catálogo do GeForce Now nesta semana
- NVIDIA teria encerrado produção da H20 depois de nova polêmica entre EUA e China
O que é o Blackwell Ultra GB300?
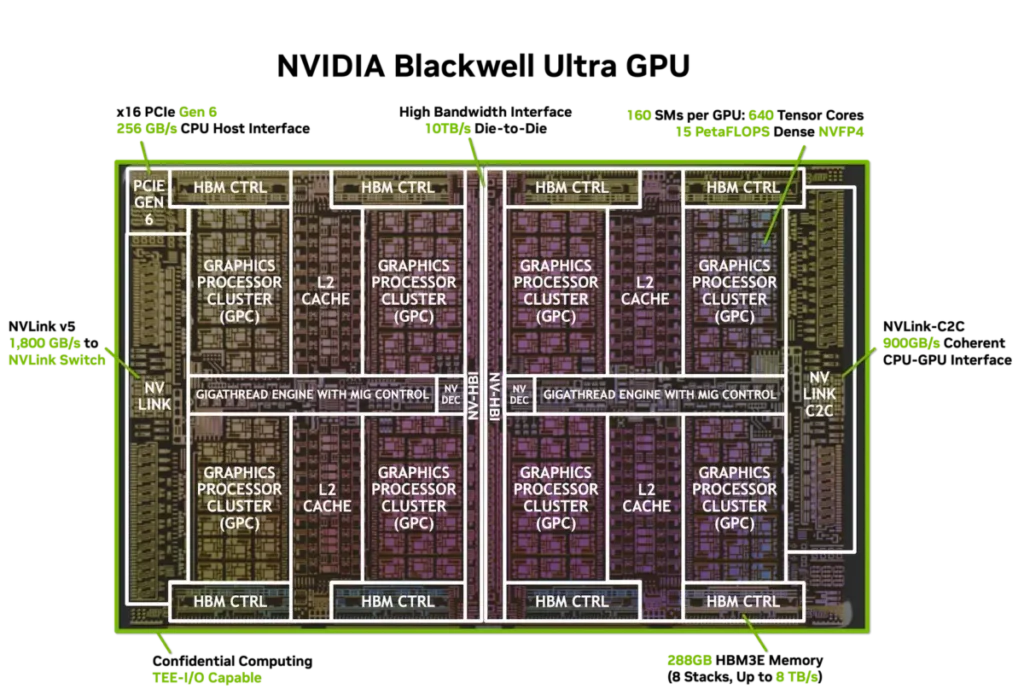
Trata-se de uma versão aprimorada que utiliza dois Dies do tamanho de um Retículo e os conecta à interface de alta largura de banda NV-HBI da NVIDIA, apresentando-os como uma única GPU. Essa GPU é bastante densa, baseada no nó TSMC 4NP (5 nm otimizado para NVIDIA), e abriga um total de 208 bilhões de transistores.
A interface NV-HBI fornece uma largura de banda de 10 TB/s para os dois Dies da GPU, tudo isso funcionando como um único chip.
A GPU NVIDIA Blackwell Ultra GB300 possui um total de 160 SMs, cada uma com 128 núcleos CUDA, quatro núcleos Tensor de 5ª Geração com computação de precisão FP8, FP6 e NVFP4, 256 KB de memória Tensor ou TMEM e SFUs. Isso são 20.480 núcleos CUDA e 640 núcleos Tensor, além de 40 MB de TMEM.
| CARACTERÍSTICA | HOPPER | BLACKWELL | BLACKWELL ULTRA |
|---|---|---|---|
| Processo de fabricação | TSMC 4N | TSMC 4NP | TSMC 4NP |
| Transistores | 80 bilhões | 208 bilhões | 208 bilhões |
| Chips por GPU | 1 | 2 | 2 |
| NVFP4 (denso | esparso) | – | 10 | 20 PetaFLOPS | 15 | 20 PetaFLOPS |
| FP8 (denso | esparso) | 2 | 4 PetaFLOPS | 5 | 10 PetaFLOPS | 5 | 10 PetaFLOPS |
| Aceleração de atenção (SFU EX2) | 4,5 TeraExponentials/s | 5 TeraExponentials/s | 10,7 TeraExponentials/s |
| Capacidade máxima de HBM | 80 GB HBM (H100) 141 GB HBM3E (H200) | 192 GB HBM3E | 288 GB HBM3E |
| Largura de banda máxima HBM | 3,35 TB/s (H100) 4,8 TB/s (H200) | 8 TB/s | 8 TB/s |
| Largura de banda NVLink | 900 GB/s | 1.800 GB/s | 1.800 GB/s |
| Potência máxima (TGP) | Até 700W | Até 1.200W | Até 1.400W |
Os Tensor Cores de 5ª Geração são responsáveis por todas as operações de computação da IA. A NVIDIA apresentou grandes inovações em cada geração de Tensor Cores para suas GPUs, como:
- NVIDIA Volta: unidades MMA de 8 threads, FP16 com acumulação de FP32 para treinamento.
- NVIDIA Ampere: formatos MMA de warp-wide completo, BF16 e TensorFloat-32.
- NVIDIA Hopper: MMA de warp-group em 128 threads, Transformer Engine com suporte a FP8.
- NVIDIA Blackwell: Transformer Engine de 2ª Geração com computação FP8, FP6, NVFP4 e memória TMEM.

Atualização de Memória
O Blackwell Ultra também traz uma grande atualização de memória, oferecendo 288 GB de capacidade HBM3e contra um máximo de 192 GB nas soluções Blackwell GB200 anteriores. Essa atualização é o que levará a NVIDIA a oferecer suporte a modelos de IA com vários trilhões de parâmetros.
A memória vem em 8 pilhas com um controlador de 16 bits de 512 bits (interface de 8192 bits) e opera a 8 TB/s por GPU, permitindo:

- Residência completa do modelo: mais de 300 bilhões de modelos de parâmetros sem descarregamento de memória.
- Contextos estendidos: maior capacidade de cache KV para modelos de transformador.
- Eficiência computacional aprimorada: maiores taxas de computação para memória para diversas cargas de trabalho.
Interconexões
A interconexão no Blackwell é a mesma NVLINK fornecida pelo switch NVLINK, NVLINK-C2C, e também há o uso da interface PCIe Gen6 x16 para conexão com GPUs host. A seguir, os recursos/especificações de conectividade do NVLINK 5 e do lado do host:
- Largura de banda por GPU: 1,8 TB/s bidirecional (18 links x 100 GB/s)
- Escalonamento de desempenho: 2x mais rápido que o NVLink 4 (GPU Hopper)
- Topologia máxima: 576 GPUs em malha computacional sem bloqueio
- Integração em escala de rack: configurações NVL72 de 72 GPUs com largura de banda agregada de 130 TB/s
- Interface PCIe: Gen6 × 16 pistas (256 GB/s bidirecional)
- NVLink-C2C: Comunicação Grace CPU-GPU com coerência de memória (900 GB/s)
| INTERCONEXÃO | HOPPER GPU | BLACKWELL GPU | BLACKWELL ULTRA GPU |
|---|---|---|---|
| NVLink (GPU-GPU) | 900 | 1.800 | 1.800 |
| NVLink-C2C (CPU-GPU) | 900 | 900 | 900 |
| Interface PCIe | 128 (Gen 5) | 256 (Gen 6) | 256 (Gen 6) |
Ganhos

A plataforma Blackwell Ultra GB300 da NVIDIA é capaz de atingir um aumento de 50% na saída de computação densa de baixa precisão usando o novo padrão NVFP4.
O novo modelo oferece precisão próxima à do FP8, e as diferenças costumam ser inferiores a 1%. O consumo de memória também foi reduzido em 1,8x em relação ao FP8 e em 3,5x em relação ao FP16.
Desempenho e segurança

O Blackwell Ultra também conta com gerenciamento avançado de agendamento e novos recursos de segurança de nível empresarial, como:
- GigaThread Engine aprimorado: agendador de trabalho de última geração que oferece desempenho aprimorado de troca de contexto e distribuição otimizada da carga de trabalho em todas as 160 Sms.
- GPU multi-instância (MIG): as GPUs Blackwell Ultra podem ser particionadas em instâncias MIG de tamanhos diferentes. Pode-se criar duas instâncias com 140 GB de memória, quatro instâncias com 70 GB ou sete instâncias com 34 GB cada, permitindo multilocação segura com isolamento de desempenho previsível.
- Computação confidencial e IA segura: extensão do Trusted Execution Environment (TEE) baseado em hardware para GPUs com recursos de TEE-I/O pioneiros do setor na arquitetura Blackwell e proteção NVLink em linha para throughput quase idêntico em comparação aos modos não criptografados.
- Mecanismo avançado do serviço de atestado remoto (RAS) da NVIDIA: sistema de confiabilidade com tecnologia de IA que monitora milhares de parâmetros para prever falhas, otimizar cronogramas de manutenção e maximizar o tempo de atividade do sistema em implantações em larga escala.
A eficiência de desempenho é outra área em que o Blackwell Ultra GB300 se destaca, oferecendo maior TPS/MW do que o Blackwell GB200, conforme mostrado nos gráficos abaixo:




Cenário da competição
A notícia mostra como a NVIDIA deve garantir o espaço de mercado para a arquitetura Blackwell ainda que já esteja planejando lançar a Rubin para o próximo ano. Porém, a empresa também precisa resolver o problema da escassez de chips.
Inclusive, esse seria um dos fatores para os preços exorbitantes das RTX 5090 e 5080. Na Kabum, uma RTX 5090 sai por valores que variam de R$ 16.399,99 (Palit RTX 5090 GameRock) a R$ 26.236,30 (Zotac RTX 5090 32gb Solid OC).
Enquanto isso, uma RX 9070 XT sai por R$ 8.023,99 (Quicksilver Gaming). Evidente que a diferença no desempenho existe, mas a diferença no valor é suficiente para muitos gamers considerarem o modelo topo de linha da AMD.
Fonte: NVIDIA.

